
The Intent behind Data Anonymization is privacy protection. Typically this is done with either encryption or removing Personally Identifiable Information (PII) from the sets of data. In theory data that has been anonymized is supposed to be irreversibly altered so that the subject can not be identified, directly or indirectly. The process of De-anonymization is when anonymous data is cross-examined with other sources of data to re-identify the anonymous data source. Not to be confused with Pseudonymization which is the process of obscuring data with the intent to be able to re-identify it later on. Storing data this way is still considered to be HIPAA compliant.
I am mainly going to focus on Genetic data for this blog. The industry of Direct-to-consumer Genetic Testing just keeps expanding. Not only do the options keep increasing for where you can test but more and more people are testing leading to larger databases. All of the big companies assure you in their privacy policies that your genetic data is safe because it is de-identified; the only problem with that is it’s not necessarily true. In most cases it is in fact de-identified (although that isn’t always the case either) however, they fail to mention that your genetic data can in fact be re-identified. There are many cases of genetic data being re-identified..way more than any of these companies would like you to know about.
In January of 2013 a researcher at the Whitehead Institute (Part of MIT) was able to track down 5 individuals who were randomly selected from a DNA database using only their DNA, ages, and the states they lived in. The worst part is it only took him a few hours. Not only that, but he was also able to find 50 relatives of the individuals. That is something important to remember: When your DNA data is exposed it isn’t just YOUR DNA but also the DNA of your descendants who will inherit a percentage of your genes. I provide more examples of re-identification in this blog.
We’ve been able to identify an individual with as little as 30 to 80 SNP’S (Single Nucleotide Polymorphisms) Keep in mind you have approximately 5 million of those, total. And it’s even easier to identify you if you are an individual with primarily Northern European heritage because this accounts for a HUGE percentage of the genomic data available on public databases. When it comes to public databases it’s easy to identify an individual if they are a third cousin match or closer. (The further removed the harder it becomes)
I am going to show you some samples from public databases after we upload raw DNA and free software we can use to analyze it. I will not be including any real names or personal information however, I will be using real raw DNA that I have permission to use.

Notice the top match (which will always be your closest in terms of relation) shares 1,720 cM’s total with our user. That puts them in the close family range. (This individual turned out to be the user’s maternal grandmother) I omitted the columns with kit numbers, names, and email addresses for privacy. Their next closest match turned out to be their third cousin 1 time removed. This match took significantly longer to discover.

Note: A Centimorgan (cM) is a unit for measuring genetic linkage, it is used to imply a distance along a chromosome, however, it should be noted that databases like GEDMatch recommend (as I do) you only consider a threshold of segments that are 7 cM and larger because any smaller and you will get matches that are Identical By State (IBS) instead of matches that are Identical By Descent (IBD)..meaning the small matching segments are just indicative of individuals from a similar population group but does not imply any sort of relevance to relation.
The main reason people upload their raw DNA is because they want to know more about their family history or to locate family. So more times than not users include their full names AND email, making it even easier to identify an anonymous user. Many of these individuals will also link their publicly accessible pedigrees. There are also sites like familysearch.org that lets you search through records, family trees, and other sources for free (after you create an account). Using two or more sources or pieces of information to identify people is called Jigsaw Re-identification. To help prove my point about the power of raw DNA combined with Open Source Intelligence (OSINT) Click here to see a list of criminals that were identified with the help of GEDmatch and Genetic Genealogists. Note: Starting in May 2019 (due to privacy complaints) GEDmatch now gives you the option to ‘opt-out’ of allowing your DNA to be involved in searches and comparisons for Law Enforcement.

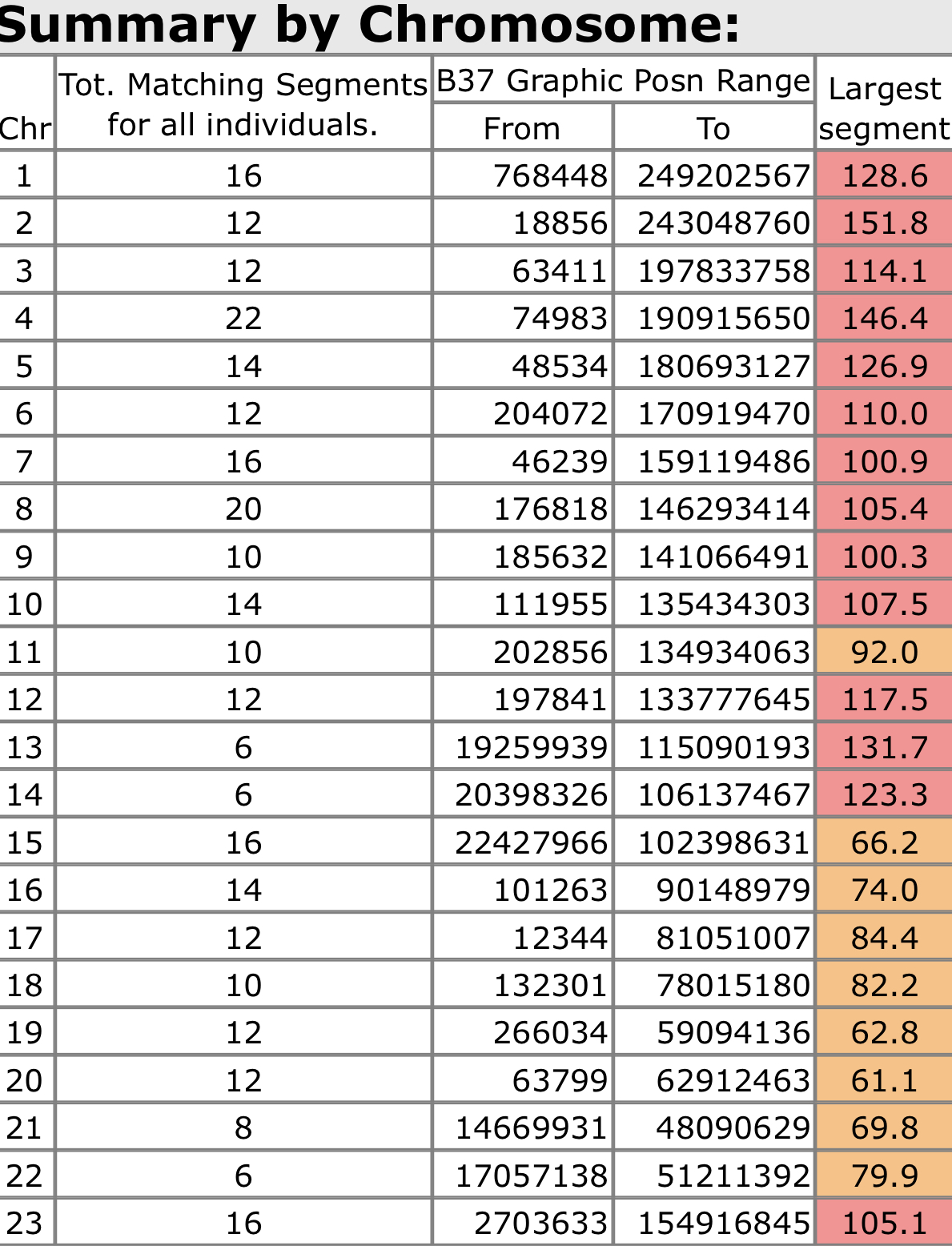
On GEDmatch you can actually compare up to 10 kits with their chromosome browser. This allows you to be able to examine matching segments between many matches all at the same time. Overlapping and matching segments can quickly indicate if there is a single common ancestor.

This is a 3D image showing matching segments on chromosome 8 of 5 different users. Two users share no segments with the other three, but the three who do sharing matching segments ended up being three generations.
Next I’m going to show samples of comparing matches on the 23rd chromosome, this is the chromosome that determines your sex. Women inherit an X-chromosome from each parent. A man inherits an X-chromosome from his mother and a Y-chromosome from his father. Most public genetic databases focus primarily on autosomal DNA. (This is DNA that is not involved in determining sex and it is not passed down in-tact from generation to generation the same way that X and Y-DNA is) All of the main direct-to-consumer genetic testing companies primarily use autosomal SNPs to determine biological closeness and ethnicity. This testing examines over 700,000 SNPs.

Here is a 3D image of an anonymous female user and her top three female matches and her X-Chomosome. Why is this beneficial? We can see there are very large segments that match with our user and two of her matches and the chunks are almost identical; this would indicate a very close relation with a very high probability and also that these matches are coming from her maternal line. Our third match has some nice size segments that she shares with our anon user. However, she shares no matching segments with the other two matches. I predicted that this match was related to the anon user on her paternal line (remember we do get an X-chromosome from our father as well as our mother) Cross examining with autosomal DNA and other matches from the paternal side I was able to confirm this.

GEDmatch does not have any tools to allow you to compare Y-DNA. However, there are free tools available online that will allow you to upload Y-STRS (Short tandem repeats, which is what is used primarily with Y-DNA..it does have SNPs but these are a lot harder to use for genealogical purposes) My favorite free software is from a company called Fluxus Engineering. (I used their phylogenetic software to analyze the Y-DNA in the image above) Their software has a very steep learning curve for anyone who doesn’t have a background in genetics. An important thing to remember about Y-DNA is that it does not recombine the same way that autosomal DNA does..the average mutation rate is 0.4% per generation..this basically means that if you take a grandfather, his son, and his grandson and look at their Y chromosome it will be practically identical from one another. Keep in mind also that Y-DNA is only the male line so none of the matches will come from the maternal side of the family. If you do not know a male’s name and you upload his Y-DNA you will more than likely find out his surname, considering most of the matches will also have his last name. (Except in cases of adoption or false paternity)
Looking at the image above you will see that one of the yellow nodes is larger than the others, that indicates a perfect match. The lines leading to the other nodes are identified with the names of the markers that the matches do NOT share with our anon user. Comparing sex chromosomes for re-identification can be tricky, but it can be a powerful tool, especially when combined with other sources.
Possibly the most alarming takeaway from the re-identification of genetic data is that even if you make the decision to NOT upload your raw data to public databases; if your family members do; it’s almost like your genetic data is out there as well. We can put together a genetic profile of someone without having their DNA as long as we have enough data of close family members. We have a lot of work to do to protect people’s genetic privacy..especially in the areas of law and security, but these companies can start by being more up front about the fact that they can truly not make the promise of anonymized data.